
Hilfe für die Datenlaube: mit [[Wikisource+Wikidata]] die freie Quellensammlung verbessern


Christopher Schwarzkopf
16. Oktober 2019
Stelle Dir eine Welt vor, in der alle historischen Quellen aus Wikisource gut sichtbar und für jeden leicht nutzbar sind, weil ihre Texte längst vollständig verschlagwortet wurden. Ein Wikisource-Katalog mit Hilfe von Wikidata, das ist unser Ziel!
Wikisource ist eine Sammlung von Texten und Quellen, die entweder urheberrechtsfrei sind oder unter einer freien Lizenz stehen; ein Qualitätsprojekt, das die Texte mit den Scans der Quelle vergleichbar macht: nach dem 4-Augen-Prinzip werden alle Texte mehrfach korrigiert. Für die eigene Forschung findet man dort auch – aber nicht nur – historisches Radfahrerwissen aus dem 19 Jahrhundert!
Ob Bibliothekskatalog oder Suchmaschine – Suchschlitze sind nützlich, um Textsammlungen oder Datenbanken zu durchsuchen. Die Suchergebnisse werden genauer, wenn die Suchfunktion mit strukturierten Metadaten arbeiten kann. Auch dafür wurde Wikidata entwickelt. Die Quellensammlung Wikisource sollte davon möglichst umfassend profitieren!
Die Frage ist nun: Wie kann Wikisource möglichst schnell durch eine “Sammlung” strukturierter Metadaten vervollständigt werden – für bessere Suchergebnisse, für eine größere Sichtbarkeit der transkribierten Texte weltweit und für wirkungsvolle Anwendungen, in denen diese Daten und Texte – z. B. Themen und Ortsinformationen – mittels Query-Service visualisiert werden können?
Ein paar Beispiele: Das zweibändige Album der Sächsischen Industrie wurde in Wikisource transkribiert und mit einer Wikidata-Abfrage in einer Landkarte Sachsens dargestellt. Für die Gartenlaube-Serie Deutschlands merkwürdige Bäume gibt es inzwischen eine Karte der Standorte, aus der wiederum ein neues Stück Wissenschaft wurde: Sachsens arboreale Merkwürdigkeiten, oder: Wie man Geschichte(n) verwurzelt (Solvejg Nitzke, 2019).
Bisher arbeiteten die beiden (deutschsprachigen) Communitys von Wikisource und Wikidata kaum zusammen. Mit [[#Wikisource+#Wikidata]] taggen wir nun – z. B. auf Twitter – Datenobjekte von und für Wikisource-Texte. Das sieht gut aus: Twitter zeigt in Vorschaubildern für Wikidata-Items die dort eingebundenen Bilder aus Wikimedia Commons.
Das Wikisource-Großprojekt Die Gartenlaube wurde von Christian Erlinger, Bibliothekar in Wien, in den vergangenen Monaten soweit wie möglich mit Quickstatements in Wikidata erschlossen. Diese neuen Datenobjekte werden nun mit Schlagworten inhaltlich erschlossen. Untertitel und Artikel-Illustrationen werden ergänzt, deren Bildunterschriften und die Datenobjekte der Illustratoren zum Beispiel. Diese Baustelle ist nicht ganz klein: Etwa 8000 Gartenlaube-Artikel-items sind noch nicht verschlagwortet und laufend kommen neue Artikelseiten hinzu – wie in den anderen laufenden Projekten von Wikisource auch. Diese Datenlaube soll wachsen und alle anderen Wikisource-Projekte damit gleich mit, durch Korrekturen, Textarbeit und Meta-Datenpflege – oder durch neue OER (Open Educational Resources) auf Grundlage der Artikel dieses Illustrierten Familienblatts.
Ein Beispiel für die Datenvisualisierung mit Wikidata ist das folgende Diagramm der Schlagworte für Artikel der bei Wikisource verfügbaren Illustrierten „Die Gartenlaube“. Wikidata-Query unter: w.wiki/3Rj
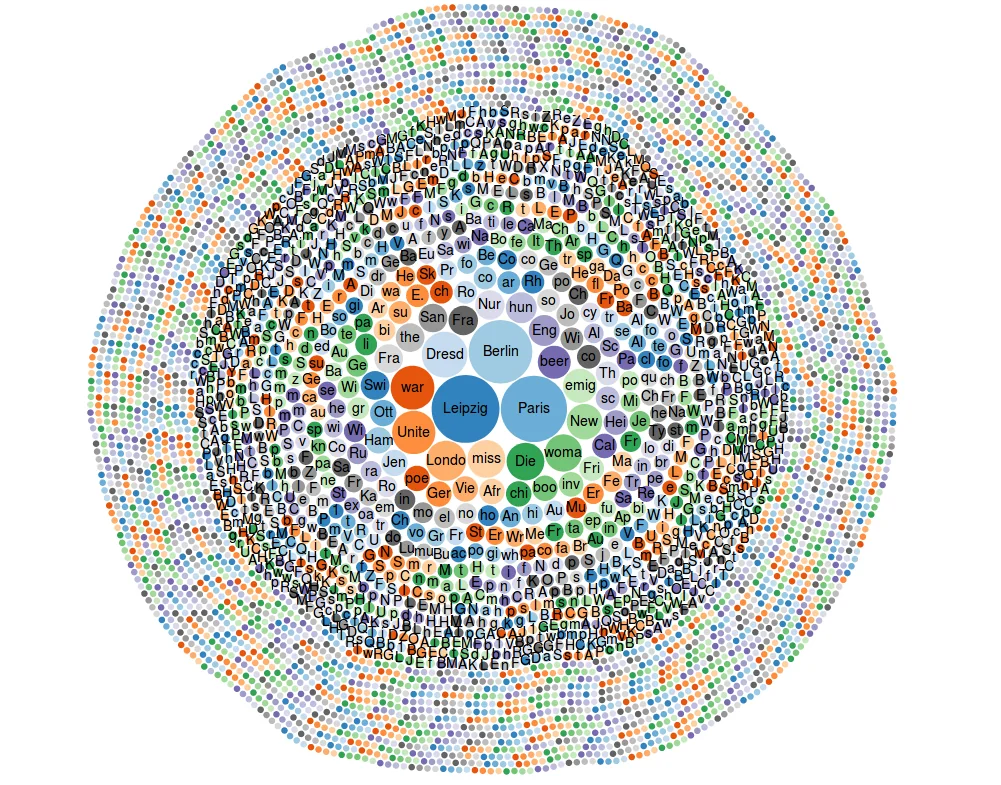
Großartig wäre es, wenn Wikimedia Deutschland mit den Communitys der beiden Portale Wikidata und Wikisource die inhaltliche Erschließung der Quellensammlung systematisch gemeinsam vorantriebe. Die neue Wikisource-Broschüre (Q66818271) ist dafür eine Basis. Langfristig könnte es ein Ziel sein, Infoboxen der Wikisource-Artikel mit Wikidata zu verknüpfen und dass die bibliographische Erschließung mit strukturierten Daten bereits beim Anlegen neuer Wikisource-Seiten geschieht. Dies ist aber noch technische Zukunftsmusik und – vermutlich – eher ein übernächster Schritt.
Für die bereits angelegten Seiten, Texte und Textsammlungen ist jetzt nachträglich bibliografische Erschließungsarbeit nötig: skriptbasiert, mit Quickstatements und/oder durch menschliche – also: intellektuelle – Schlagwortvergabe. Die Mischung macht’s.

Zum Autor:
Jens Bemme arbeitet im Referat Saxonica an der Sächsischen Landesbibliothek – Staats- und Universitätsbibliothek Dresden (SLUB). Sein Forschungsinteresse gilt insbesondere altem Radfahrerwissen in historischen Tourenbüchern für Radfahrer und anderer Radfahrerliteratur um 1900 sowie europäischen Perspektiven auf Heimatforschung mit offenen Daten und offenen Werkzeugen. Jens ist Stipendiat im Programmjahr 2019/2020 des Fellow-Programms Freies Wissen. Hier setzt er das Projekt
“More than cycling: Europäische Heimatforschung – ein Ansatz für offene Daten und Narrative, samt Fernwehforschung und Radfahrerwissen“




_001.jpg){kind=link}
== Lesetipp == 'How can Structured Data on Commons, Wikidata, and Wikisource walk hand in hand? A pilot project with Punjabi Qisse' https://space.wmflabs.org/2019/12/07/how-can-structured-data-on-commons-wikidata-and-wikisource-walk-hand-in-hand-a-pilot-project-with-punjabi-qisse/
[…] Projekt Gartenlaube ist dabei nur ein Beispiel für die Vielfalt an Funktionen, die einem die Wiki-Seiten bieten […]
Für das 'Reichsgesetzblatt (bis 1871 Bundes-Gesetzblatt des Norddeutschen Bundes)' wird Hilfe gesucht: https://de.wikisource.org/wiki/Diskussion:Reichsgesetzblatt_(Deutschland)#Scans_der_Gesetzestexte . Ziel und Aufgabe: die Metadaten der Transkiptionen in Wikidata anlegen und ergänzen.
Ein Repositorium für Die Datenlaube: https://github.com/DieDatenlaube, mit [[#Wikisource+#Wikidata]]