

Maria Lechner
22. September 2022
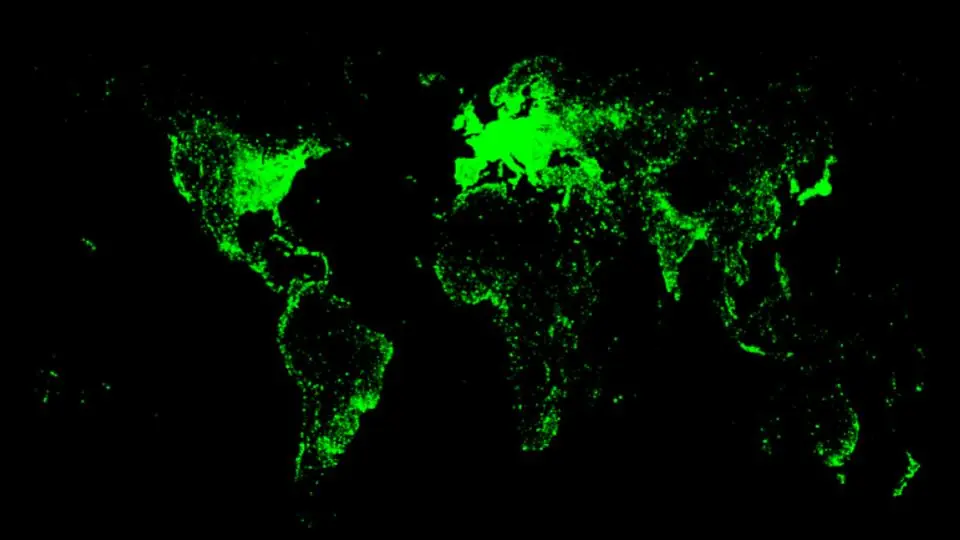
Mit Blick auf obiges Bild taucht vielleicht die Frage auf: Was sehe ich hier eigentlich? Eine Abbildung von Lichtverschmutzung? Eine Datenvisualisierung der Suchanfragen zu der neuen „Der Herr der Ringe“-Serie? Auf den zweiten Blick kommt vielleicht eine weitere Frage in den Sinn: Was sehe ich hier eigentlich nicht? Nach einiger Spekulation wird womöglich ein Schluss gezogen. Der Blick auf die Welt: wohl eingeschränkt. Das Bild der Welt: kaum ausgeleuchtet.
Es handelt sich übrigens weder um die Darstellung von Lichtverschmutzung, noch um die Search Queries zu dem neuesten Streaminghit. Das Bild zeigt auf, wie wenige Frauen in Wikipedia und Wikidata vertreten sind. Salopp gesagt, findet sich jeder Eintrag über eine Frau als kleiner grüner Punkt auf dem Bild repräsentiert. Oder aber genauer: jeder Datensatz in Wikidata, der die Eigenschaft „female“ („weiblich“) hat, wird anhand seiner als Koordinaten hinterlegten Eigenschaft „Place of Birth“ („Geburtsort“) auf der Karte verortet. Es ist also viel weniger ein Abbild als ein Zerrbild unserer Welt. Denn wir wissen intuitiv: So sieht unsere Gesellschaft nicht aus. Wie jedoch entsteht diese Diskrepanz? Wie kann dieser entgegengesteuert werden? Welche anderen Personen, Dinge und Geschichten liegen noch im Dunkeln? Wie können diese nicht nur angeleuchtet werden, sondern von sich aus strahlen? Und allen voran: Warum sind diese Fragen so wichtig?
Offene Daten, wie Wikidata sie bereitstellt, stehen nicht für sich allein sondern bilden oftmals Grundlage und Trainingskorpus von Algorithmen und Machine-Learning-Systemen. Diese wiederum formen das gesellschaftliche Zusammenleben auf unterschiedliche Weise. Eine Vielzahl kommerzieller Machine-Learning-Systeme greifen auf Wikidata zu und verwenden die vorhandenen, offenen Daten. Das bedeutet, dass sowohl Fehler als auch schlichtweg fehlendes Wissen dadurch reproduziert werden. Leerstellen wachsen, gebaute (Wissens-)Strukturen verfestigen sich. Die digitale Welt bildet nicht nur die vermeintlich reale Welt ab, sondern wirkt dahin zurück. Finden Teile der Welt keinen Einzug in die digitale Repräsentation, nehmen wir als Menschengemeinschaft uns selbst Potenzial: Potenzial für Wachstum, Innovation, Problemlösung für globale Herausforderungen wie etwa die Klimakrise aber auch für Weiterentwicklung, Interkulturelle Kommunikation und Poesie.
Unsere Arbeit, so digital sie auch sein mag, hat Auswirkungen in der realen Welt, auf reale Menschen.Franziska Heine, geschäftsführende Vorständin von Wikimedia Deutschland
Das betrifft nicht nur die zuvor angesprochene Problematik der Geschlechterrepräsentation in Wikidata und Wikipedia. Auch nicht-westliches Wissen ist stark unterrepräsentiert. Beispielsweise sind mehr als 95% der Menschen, über die in Wikidata und Wikipedia geschrieben wird, im globalen Norden geboren. Auch hier wird eine wertvolle, vielfältige Wissensressource nicht ausgeschöpft. Dem entgegenzusteuern ist nicht Kür, sondern Pflicht.
Offene Daten für eine offene Welt. Gerechte Daten für eine gerechte Welt.
Technologie, wie Wikimedia sie versteht, ist niemals nur Werkzeug, sondern auch Möglichkeitsraum. Dieser bietet die Chance, die herrschende Definition von Wissen zu reflektieren und neu zu denken.
Das Bewusstsein über Wissens(un)gerechtigkeit bildet den Startpunkt. Die Anerkennung, dass auch von Wikimedia produzierte Software überwiegend auf westlichen Traditionen der Wissensgenerierung und -vermittlung baut, bildet den ersten Schritt. Die Herausforderungen auf dem Weg sind vielfältig. Wie kann Wissen abgebildet werden, das nicht der westlichen Auffassung von Wissensvermittlung entspricht? Wie können Geschichten dargestellt werden, die nicht durch Bücher, sondern beispielsweise durch mündliche Erzählungen überliefert wurden? Wie kann ein zuverlässiges Zitationssystem dazu aussehen?
Die Verlagerung von Gestaltungs- und Entscheidungsmacht zu Gemeinschaften, die derzeit kaum Repräsentation in Wikipedia und Wikidata finden, ist dafür zentral. Das schafft die Möglichkeit der Entwicklung von Softwarearchitektur und Tools, die diesen Anforderungen gewachsen sind. Um das zu erreichen, unterstützt Wikimedia aktiv Gruppen, die sich diesen Problemstellungen annehmen und deren Ziel es ist, unterrepräsentiertes Wissen in Wikipedia und Wikidata sichtbar zu machen.
Das Unrecht mit Daten visualisieren.
Beispiele, die das Potenzial aufzeigen, gibt es bereits. Das Projekt Enslaved: Peoples of the Historical Slave Trade baut auf Wikibase, der Softwarearchitektur hinter Wikidata. Hier bildet Wikibase die technische Grundlage, verschiedene relevante Datenbanken miteinander zu verbinden. Wissenschaftler*innen können so zusammen Daten über versklavte Menschen sammeln. Die derzeit 5 Millionen Datensätze zeichnen ein detailliertes Bild von dem Leben versklavter Menschen und lassen diejenigen sprechen, die viel zu lange nicht gehört wurden.

Auch über Wikimedia-Projekte hinaus finden sich Projekte, die vermeintlich „herkömmliche“ Annahmen über Wissensstruktur und -vermittlung herausfordern. Mapeo beispielsweise lässt indigene Völker ihre angestammten Territorien auf einfache Art und Weise geografisch kartieren. Die App wurde zusammen mit indigenen Gemeinschaften entwickelt, die sich Gefahren wie Landraub, Wilderei, Ölverschmutzung und Ähnlichem ausgesetzt sehen. Wie machtvoll digitale Werkzeuge wie Mapeo sein können, zeigt sich am Beispiel der Waorani in Ecuador. Sie sahen sich aufgrund von geplanten Ölbohrungen mit einem potenziellen Verlust von einer halben Million Hektar ihrer Heimat, dem Amazonas-Regenwald, konfrontiert. Mit Hilfe von Mapeo gelang es den Waorani jedoch, darzustellen, dass es sich bei dem Gebiet um einen kulturellen Schatz reich an Stammeswissen und -geschichte handelte. Die drohende Gefahr konnte abgewendet werden.
Beide Projekte veranschaulichen die Vielfalt in Inhalt und Form von Wissen, das der Weltgemeinschaft potenziell entgeht. Es handelt sich nicht nur um eine reine Repräsentation der Vollständigkeit zuliebe, sondern um Wissen, das unsere Welt formt und unsere Umwelt direkt beeinflusst. Sie legen auch die Herausforderungen dar, die sich die derzeit herrschende Vorstellung von Wissensstruktur und -vermittlung stellen müssen. Diesen Herausforderungen mit Neugier und Lust am Gestalten zu begegnen, ist zentral, um unser Weltwissen von Voreingenommenheit zu befreien.
Dieser Blogbeitrag baut auf die Keynote „How biased is our knowledge of the world and why?“ von Franziska Heine, geschäftsführende Vorständin bei Wikimedia Deutschland. Die Keynote fand am 31. August 2022 im Zuge der „Data Natives“ Konferenz in Berlin statt.



