
Wie macht man 5 Millionen wissenschaftliche Open-Access-Abbildungen frei nutzbar?

Christopher Schwarzkopf
26. März 2019
NOA steht für „Nachnutzung von Open-Access-Abbildungen“, ein von der DFG seit 2017 gefördertes Projekt, dessen Antragsdokument ganz im Stil von Open Science bereits vor der Begutachtung hier verfügbar gemacht wurde. Das Open Science Lab der Technischen Informationsbibliothek (TIB) ist neben der Hochschule Hannover Projektpartner, ferner gibt es Wikimedia als Unterstützer des Projektantrags. Eine kurze Einführung zu NOA ist bereits hier erschienen. Wir haben früh damit begonnen, das Projekt und die Zwischenergebnisse mit der Wikimedia-Community zu diskutieren, so z.B. bei der Wikicite 2016 und Wikicite 2018. Letzte Woche haben wir die neuen NOA-Funktionen und die Zusammenarbeit mit der Community auf dem Bibliothekartag vorgestellt.
NOA versucht, Bilder aus wissenschaftlichen Open-Access-Artikeln nachhaltig für die Nachnutzung zu erschließen. Dafür werden in großem Stil Artikel von verschiedenen Verlagen heruntergeladen. Die meisten dieser Artikel sind in englischer Sprache. Alle natürlich mit einer Creative-Commons-Lizenz, und zwar meistens CC-BY. Damit können die Inhalte frei verbreitet und verändert werden, solange der ursprüngliche Urheber genannt wird und Änderungen gekennzeichnet werden. Deshalb ist diese Lizenz auch mit Wikimedia Commons kompatibel. Aus den heruntergeladenen Artikeln werden nun die Links zu den Bildern sowie die Bildunterschriften extrahiert. Zusätzlich werden auch alle relevanten Metadaten der Artikel extrahiert – zum Beispiel Autoren, Titel oder Zeitschriftennnamen.
Später werden die Bilder mit maschinellen Methoden inhaltlich erschlossen. Dazu soll herausgefunden werden, welche Kategorien aus Wikipedia und Wikimedia Commons ein einzelnes Bild beschreiben. Bekannt sind schon die Bildunterschriften und der Kontext, in dem das Bild im Artikel erwähnt wird. Aus diesen Absätzen werden nun die für das Bild wichtigen Terme extrahiert. Dann wird die englische Wikipedia nach diesen Termen durchsucht und es werden die Artikel gefunden, in denen die Terme am häufigsten vorkommen. Dabei werden seltenere Terme höher gewichtet. Wenn in einer Bildunterschrift ein eher häufiges Wort wie „year“ benutzt wird, bedeutet das also nicht automatisch, dass ein Artikel, in dem das Wort oft auftaucht, für das Bild relevant ist. Bei weniger gebräuchlichen Wörtern wie “Glycosaminoglycans” ist es schon wesentlich wahrscheinlicher, dass ein Artikel, in dem dieses Wort vorkommt, das gleiche Thema behandelt wie das Bild. Wenn in einer Wikipediakategorie viele solcher Artikel vorkommen, wird diese Kategorie als Beschreibung für das Bild verwendet. Wer sich für diese Methoden im Detail interessiert, kann das hier nachlesen. Über die Wikidata API kann ermittelt werden, welches Wikidata Item zu dieser Kategorie gehört, sowie welche Kategorie aus Wikimedia Commons dazu passt.
Somit halten wir an jedem Bild Informationen in drei (!) Systematiken vor, und zwar auch deshalb, weil momentan auch bei Wikimedia Commons umgebaut wird: In Zukunft sollen die Kategorien auf Commons durch mehrsprachige strukturierte Beschreibungen ersetzt werden, was im Moment im Projekt Structured Data getestet wird. Um in das neue Datenformat zu passen, müsste sich auch unsere Erschließung anpassen. Da es bei Structured Commons vor allem darum geht, mithilfe von Wikidata zu beschreiben, was auf einem Bild dargestellt wird, könnte unsere automatische Erschließung an ihre Grenzen stoßen. Wissenschaftliche Abbildungen bilden oft Informationen anstatt klar abgegrenzter visueller Entitäten ab, sodass es schon für Menschen schwer zu formulieren ist, welches Konzept abgebildet wird, geschweige denn für Maschinen. Damit auch Abbildungen wie unsere zukünftig effektiv beschrieben werden können, haben wir schon Feedback auf den Diskussionsseiten gegeben. Es sollte ein intensiverer Austausch von Structured Commons und NOA angestrebt werden. Wir stehen dafür bereit!
Die Bilder können über eine Suchmaschine gefunden werden. Generell sind wir keine Fans von Silos, die nicht mit anderen Datenquellen verknüpft sind und Nutzende zwingen, ständig neue Plattformen zu erlernen. Wir haben uns trotzdem dafür entschieden, eine eigene Suchmaschine zu entwickeln, da es ein langer Prozess ist, bis die Bilder auf Wikimedia Commons verfügbar sind und sie schon zuvor für alle zugänglich sein sollten.
Ein Suchergebnis sieht zum Beispiel so aus:
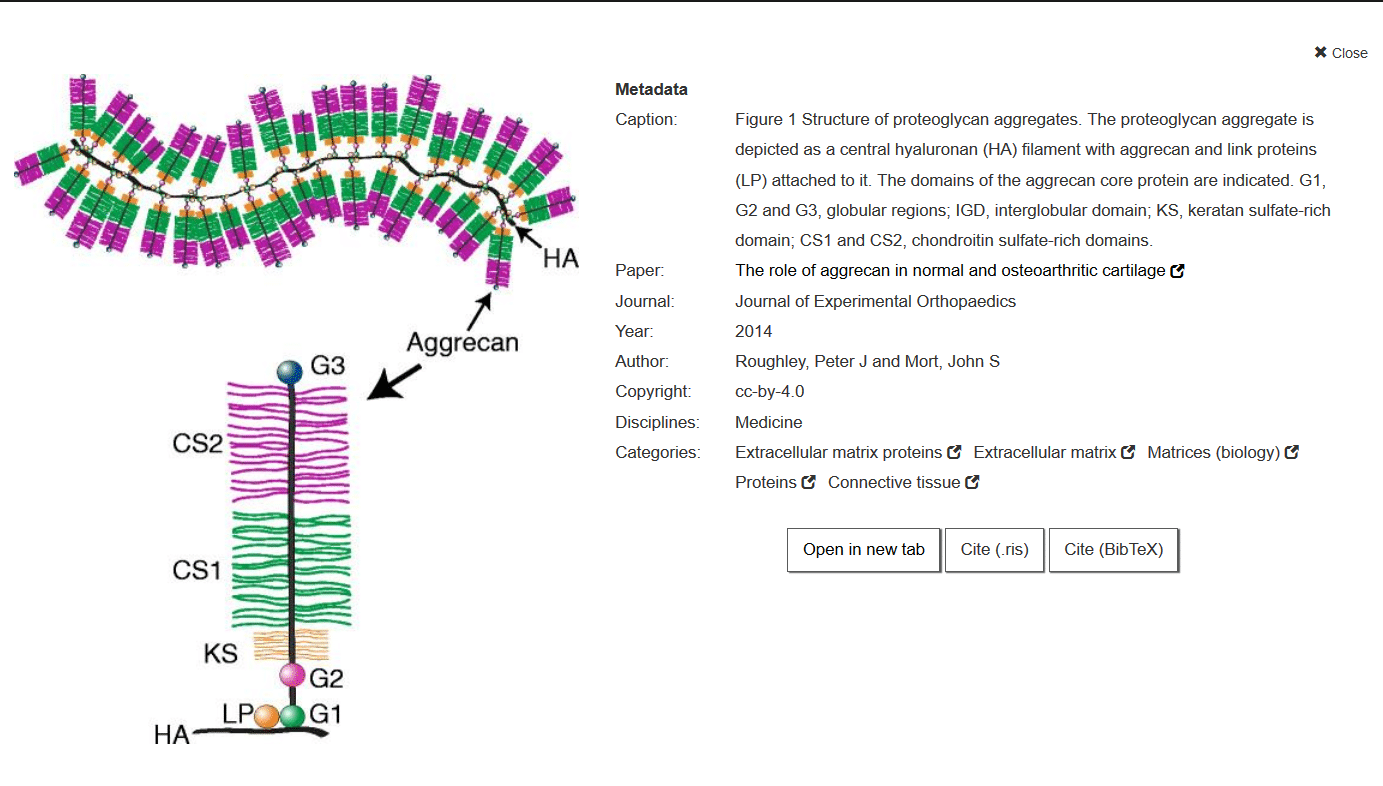
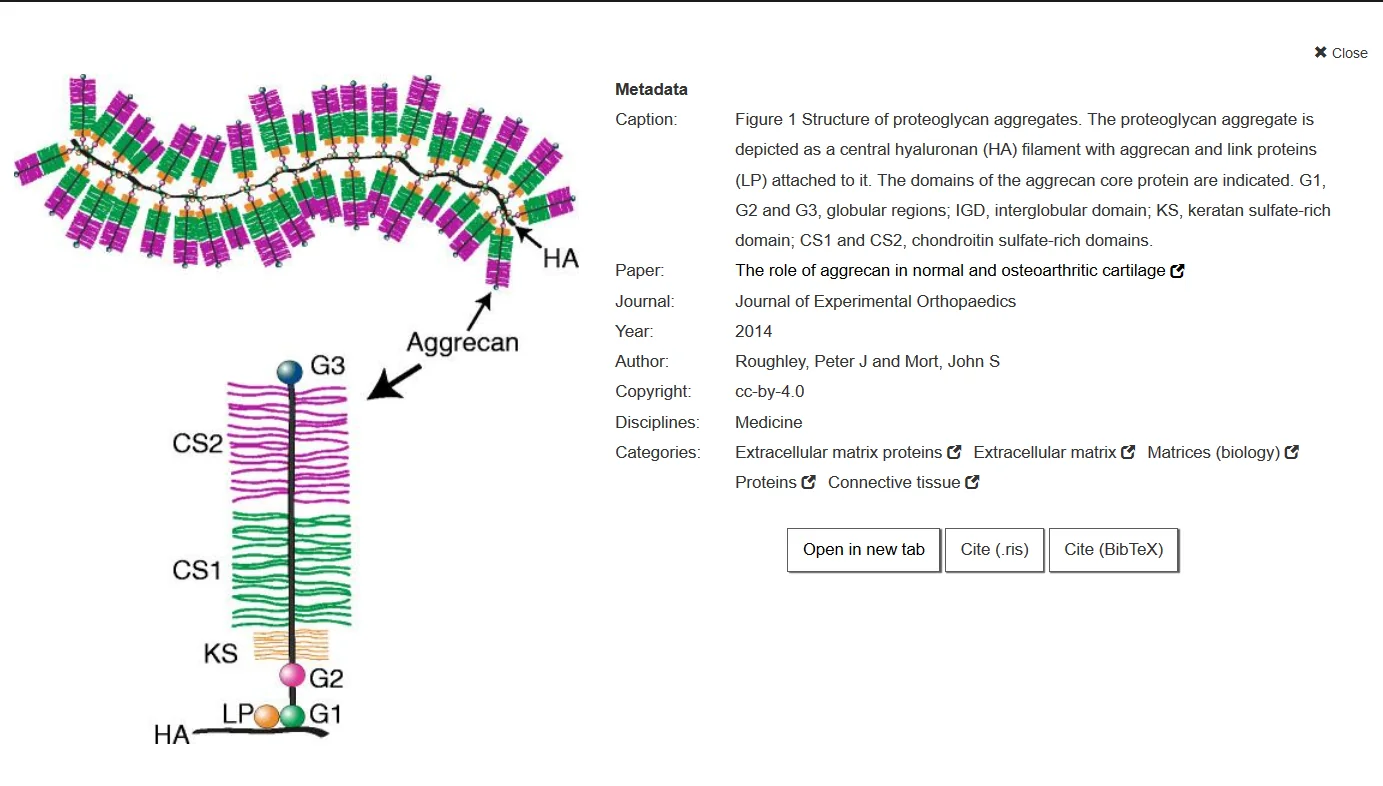
Screenshot aus der Suchmaschine. Bild aus: Roughley, Peter J and Mort, John S „The role of aggrecan in normal and osteoarthritic cartilage“, Journal of Experimental Orthopaedics doi:10.1186/s40634-014-0008-7
Warum werden nicht alle Bilder auf einmal hochgeladen?
Es ist also eine große Menge von Bildern mit beschreibenden Metadaten vorhanden. Ferner gibt es zum Upload großer Mengen an Bildern nach Wikimedia Commons mehrere Tools, zum Beispiel Pattypan und das GLAMwiki Toolset. Technisch ist es also möglich, alle Bilder bereits jetzt hochzuladen. Was hat uns also davon abgehalten, genau das zu tun?
Durch Austausch mit Verantwortlichen vorangegangener Projekte mit ähnlicher Intention wussten wir, dass die Community bei Massenuploads sehr auf die Qualität bedacht ist und diese nicht ohne vorherige Rücksprache gestartet werden sollten. Außerdem ist nur ein Teil der Bilder zur Nachnutzung geeignet:
Ein erste Herausforderung ist das Urheberrecht. Während die meisten Bilder formalisierte Lizenzen wie CC-BY-4.0 haben, gibt es einige, die die Nachnutzungsrechte nur in einem Fließtext beschreiben oder eine Lizenz benutzen, die nicht zum Upload auf Commons geeignet ist. Nachdem solche Bilder aussortiert wurden, bleiben welche mit einem ganz anderen Problem: Manche Autorinnen und Autoren verwenden Bilder, die nicht unter einer freien Lizenz stehen, zum Beispiel von kommerziellen Bilddatenbanken. Andere zitieren Bilder aus Veröffentlichungen von anderen Autoren. Letztere können – aber müssen nicht – unter einer freien Lizenz stehen. Auch dann stimmen aber die Metadaten nicht mehr, da die Quelle des Bildes ein ganz anderer Artikel ist als der, aus dem es extrahiert wurde. Auch diese Problemfälle können mit einem Algorithmus aussortiert werden, aber eine hundertprozentige Sicherheit gibt es hier nicht.
Die zweite Herausforderung ist die Relevanz und Verständlichkeit der Bilder. Viele sind nur im Kontext des Artikels überhaupt zu verstehen und / oder außerhalb des Artikels nicht relevant. Beispiele sind Bilder, die Karten mit untersuchten Orten zeigen, oder Bilder, die einen Graphen zeigen, der mit „Results from the experiment“ ohne weitere Informationen beschrieben wird. Andere haben eine schlechte Auflösung oder zeigen nur Text. Abgesehen von solchen offensichtlichen Problemfällen gibt es auch viele Bilder, bei denen die Relevanz nur schwer eingeschätzt werden kann. Projektmitarbeitende ohne Fachwissen in der entsprechenden Domäne können oft nicht erfassen, was genau auf einem Bild eigentlich gezeigt wird, geschweige denn einschätzen, ob die Inhalte später für andere nützlich sein könnten.
-

- Bild mit schlechter Auflösung. Zhao, Xiaolei et al. „Application of Spontaneous Photon Emission in the Growth Ages and Varieties Screening of Fresh Chinese Herbal Medicines“, Evidence-Based Complementary and Alternative Medicine doi:10.1155/2017/2058120
-

- Bild mit ausschließlich Text. Brodić, Darko and Milivojević, Zoran N. and Maluckov, Čedomir A. „Recognition of the Script in Serbian Documents Using Frequency Occurrence and Co-Occurrence Analysis“, The Scientific World Journal doi:10.1155/2013/896328
Wie lösen andere die Probleme?
NOA ist nicht das erste Projekt, das sich mit Massenuploads auf Wikimedia Commons beschäftigt. Andere Projekte haben auch schon Medien aus Open-Access-Artikeln hochgeladen:
- Der Open Access Media Importer Bot hat einige Jahre lang alle Artikel von PubMedCentral (Datenbank für Open-Access-Publikationen in den Lebenswissenschaften) gecrawlt und Ton- und Videodateien nach Wikimedia Commons importiert. Eine engere Auswahl wurde dabei nicht getroffen. Da solche Medienformate in Artikeln selten sind, handelt es sich aber auch nur um etwas unter 40.000 Dateien. Uploads finden durch einen Bot statt.
- Der Recitation Bot hat als Teil des Projekts “Signalling OA-ness” auf Wikipedia Medien aus Open-Access-Artikeln hochgeladen, die auf Wikipedia zitiert wurden. Die Auswahl wird also darüber getroffen, ob Artikel bereits in anderen Kontexten für die Wikimediaprojekte relevant waren. Das ist elegantes Mittel, um zu bestimmen, ob Material für Nutzer*innen wichtig ist.
Im Projekt hatten wir auch eigene Ideen, wie die richtigen Bilder ausgewählt werden könnte. Man könnte versuchen, anhand der Bildbeschreibungen oder vielleicht sogar anhand des Bildinhaltes einen Machine-Learning-Algorithmus zu trainieren, der die relevanten Bilder herausfiltert. Oder wir könnten die Bereiche auf Wikipedia suchen, wo besonders viele Artikel keine Bilder haben. Ein ähnliches Tool gibt es schon für Wikidata Items, die kein zugehöriges Bild haben.
Unsere Lösung
Vielleicht gibt es auch noch ganz andere Kriterien, anhand derer die Relevanz für Wikimedia Commons beurteilt werden kann. Bisher gibt es aber vor allem einen Grund, weshalb Bilder dort landen: Irgendjemand findet, dass ein Bild auf Commons sein sollte und lädt es hoch.
Dieses Kriterium soll auch bei den NOA-Bildern angewendet werden. Nutzende von Wikimedia Commons sollen selbst entscheiden können, welche der Bilder hochgeladen werden. Damit dies möglichst einfach ist, haben wir zwei verschiedene Uploadmöglichkeiten entwickelt. Dabei haben wir uns von zwei anderen Tools inspirieren lassen, die ebenfalls Bilder von einem anderen Dienst zu Wikimedia Commons hochladen. FlickrFree, das frisch hochgeladene, frei lizenzierte Bilder aus Flickr anzeigt und den Upload mit einem Klick ermöglicht, und Flickr2Commons, auf Flickr gefundene Bilder unkompliziert hochgeladen werden können. Unsere zwei Lösungen sind ähnlich, unterscheiden sich aber unter anderem dadurch, dass sie in die Suchmaschine integriert sind.
1. Upload nach einer Suche
Wer in der Suchmaschine nach einem Bild sucht, bekommt unter den einzelnen Ergebnissen einen Button mit Aufschrift „Upload to Wikimedia“ angezeigt. Nach einem Klick hier drauf wird man aufgefordert, sich mit seinem Wikimedia-Account anzumelden und NOA zu erlauben, Bilder hochzuladen. Nachdem das geschehen ist, kann man aus den ermittelten Kategorien die passenden markieren und mit einem Klick auf „Upload“ das Bild mit allen Daten zu Wikimedia Commons hochladen. Das Ergebnis erscheint als Link und man kann es sich direkt ansehen und bei Bedarf editieren.
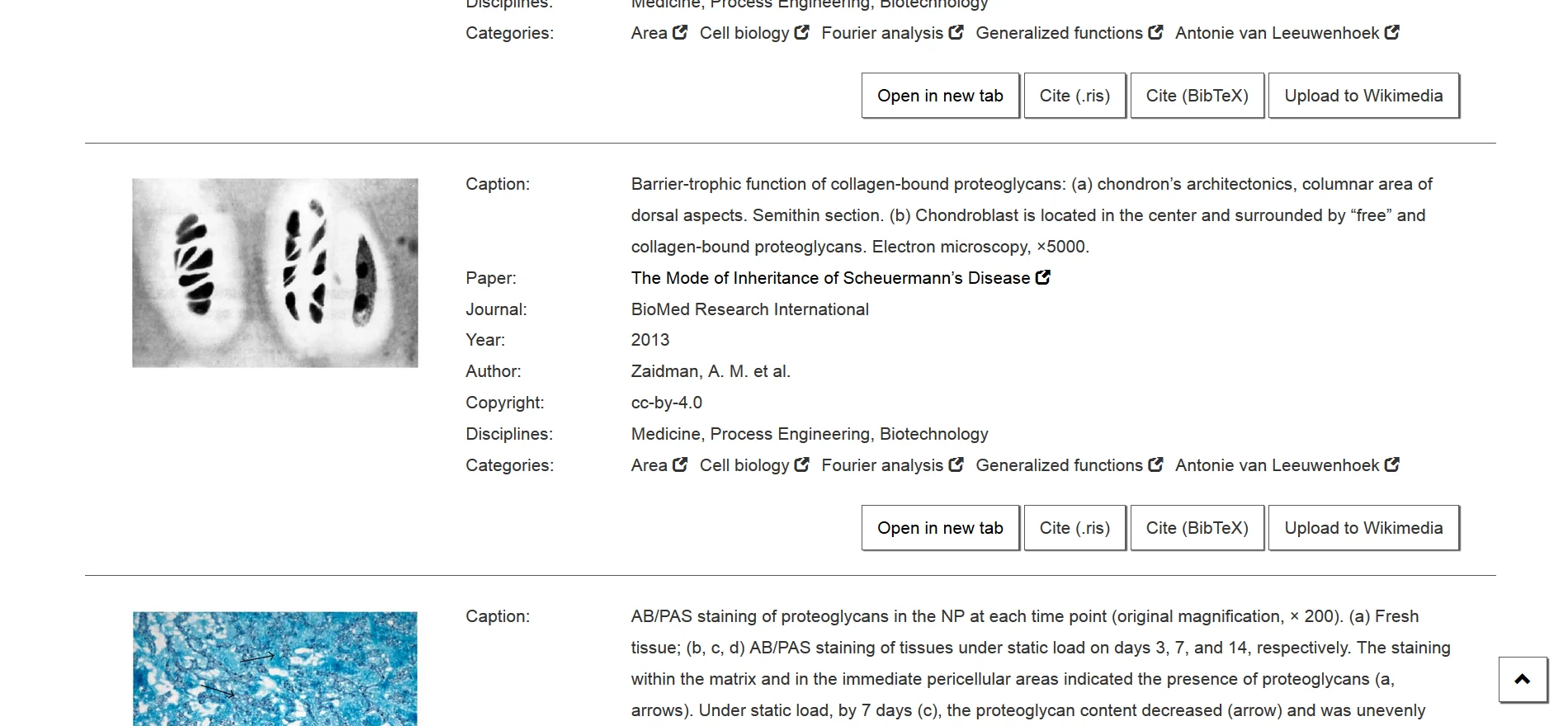
Suchergebnisse in der NOA-Suchmaschine, Screenshot. Bild aus: Li, Qingwen et al. „Analysis of the Blasting Compaction on Gravel Soil“, Journal of Chemistry doi:10.1155/2015/642810
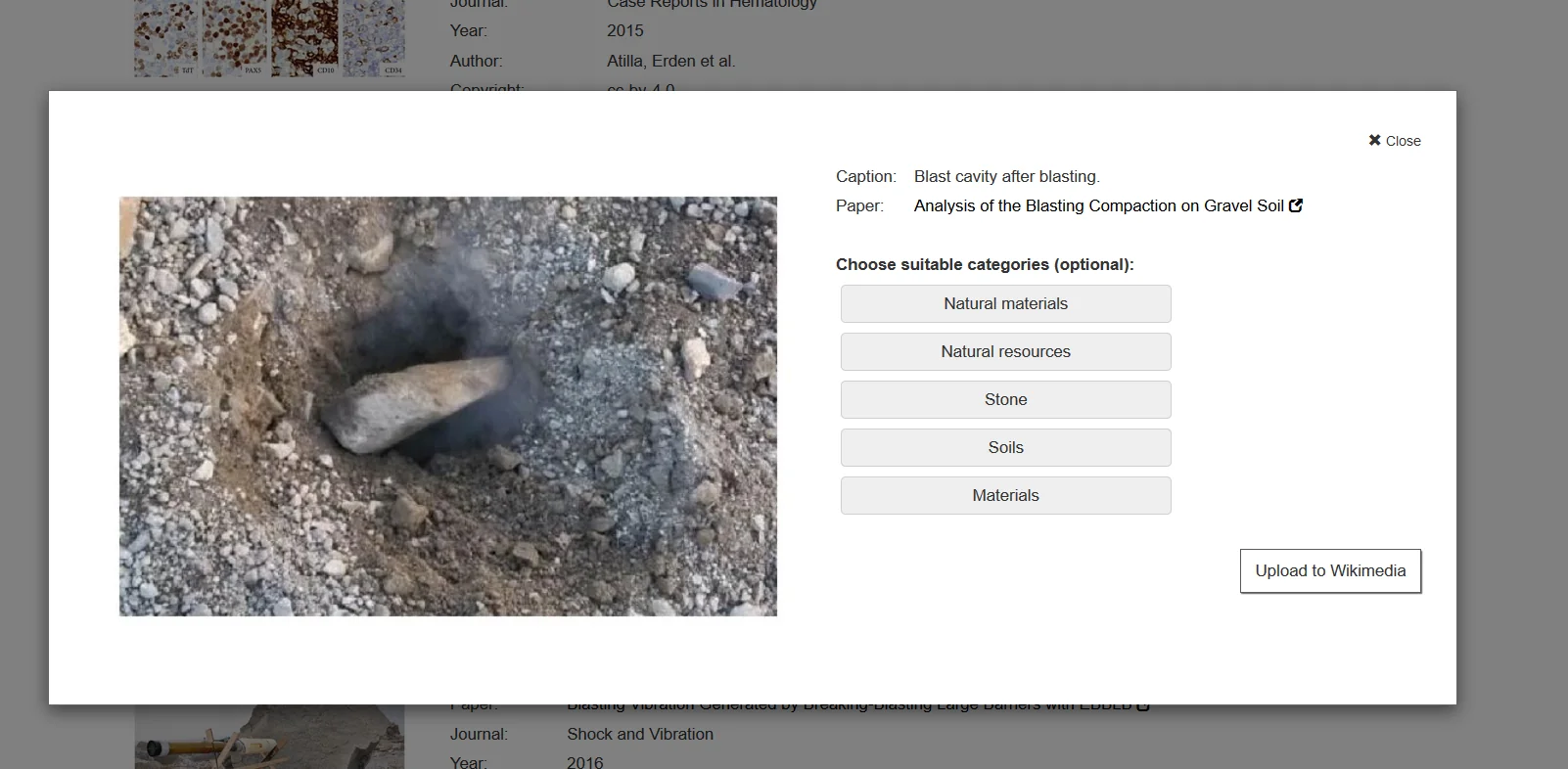
Uploadfunktion in der NOA-Suchmaschine, Screenshot. Bild aus: Li, Qingwen et al. „Analysis of the Blasting Compaction on Gravel Soil“, Journal of Chemistry doi:10.1155/2015/642810
https://www.youtube.com/watch?v=yS_UNRBroMU
2. Das Random Upload Tool
Wer kein bestimmtes Thema im Kopf hat, aber dennoch dazu beitragen will, Bilder aus dem Projekt nach Wikimedia Commons zu transferieren, kann das Random Upload Tool benutzen. Dort bekommt man zufällig ausgewählte Bilder angezeigt und kann mit einem Klick bestimmen, ob das Bild hochgeladen wird, oder ob ein neues Bild angezeigt werden soll. Wird ein Bild nicht hochgeladen, wird es zunächst nicht mehr angezeigt. Auch hier ist es möglich, passende Kategorien zu einem Bild auszuwählen. Außerdem kann die Anzeige der Bilder nach Fachgebiet eingeschränkt werden. Medizin ist standardmäßig herausgefiltert, weil es hier eine Menge Bilder gibt, die viele Menschen möglicherweise nicht gerne sehen möchten. Das Fach kann aber beim Fächerfilter ausgewählt werden.
Random Upload Tool, Screenshot. Bild aus: Acikgoz, Hakan et al. „Improved control configuration of PWM rectifiers based on neuro-fuzzy controller“, SpringerPlus doi:10.1186/s40064-016-2781-5
In Zukunft
In Zukunft wollen wir weitere Möglichkeiten entwickeln, die Bilder noch zielgenauer hochzuladen. Eine Idee wäre, Wikipediaartikel ohne Bilder zu finden und automatisch passende Bilder vorzuschlagen. Ein ähnliches Tool gibt es bereits für Wikidata. Es ist auch vorstellbar, Autorinnen und Autoren direkt beim Erstellen der Artikel zu unterstützen und anhand des neu geschriebenen Textes relevante Bilder vorzuschlagen. Vielleicht kann auch ein Algorithmus trainiert werden, der aus den hochgeladenen Bildern lernt und selbstständig entscheidet, welche Bilder geeignet sind. Die können dann entweder automatisch hochgeladen werden, oder Nutzende zum Upload vorgeschlagen werden.
Um die Zahl der relevanten Bilder zu erhöhen, sollen auch neue Quellen erschlossen werden. Bisher ist die Sammlung in NOA sehr einseitig in Richtung der Ingenieur- und Lebenswissenschaften. Geistes- und Sozialwissenschaften sind kaum vertreten. Wenn diese eingeschlossen werden, kann das Projekt einen Mehrwert für ganz neue Nutzergruppen schaffen.
Mitmachen
Je mehr Leute mitmachen, desto mehr Bilder können für alle über Wikimedia Commons zugänglich gemacht werden. Ob jemand nun über die Suche oder über das Random Upload Tool ein schönes Bild findet – das Hochladen ist einfach. Alles, was man dafür tun muss, ist, diese Funktion in seinem Wikimedia Account zu erlauben (das kann natürlich jederzeit rückgängig gemacht werden). Jeder Beitrag ist willkommen.
Was uns auch eine große Hilfe ist, sind Rückmeldungen aller Art: Wie wird das Projekt insgesamt gesehen? Wie ist die Qualität der Bilder? Was fehlt bisher komplett? Welche Funktionen könnte sonst noch eingebaut werden?
Wir freuen uns über eure Meinungen!




[…] Gehören überhaupt alle Bilder auf Wikimedia Commons? In diesem Beitrag, der ursprünglich auf dem Blog von Wikimedia Deutschland erschienen ist, beschreiben Lucia Sohmen, Ina Blümel und Lambert Heller vom Open Science Lab der […]
[…] all the images belong there at all? In this article, that was originally published in German on the Wikimedia Deutschland blog, Lucia Sohmen, Ina Blümel, and Lambert Heller from the Open Science Lab at TIB describe their […]