
Improving data quality on Wikidata – checking what we have

Lydia Pintscher
13. March 2015
 Hello, we are the Wikidata Quality Team. We are a team of students from Hasso Plattner Institute in Potsdam, Germany. For our bachelor project we are working together with the Wikidata development team to ensure high quality of the data on Wikidata.
Hello, we are the Wikidata Quality Team. We are a team of students from Hasso Plattner Institute in Potsdam, Germany. For our bachelor project we are working together with the Wikidata development team to ensure high quality of the data on Wikidata.
Wikidata provides a lot of structured data open to everyone. Quite a lot. Actually, they are providing an enormous amount of data approaching the mark of 13.5 million items, each of which has numerous statements. The data got into the system by diligent people and by bots, and neither people nor bots are known for infallibility. Errors are made and somehow we have to find and correct them. Besides erroneous data, incomplete data is another problem. Imagine you are a resident of Berlin and want to improve the Wikidata item about the city. You go ahead and add its highest point (Müggelberge), its sister cities (Los Angeles, Madrid, Istanbul, Warsaw and 21 others) and its new head of government (Michael Müller). As you do it the correct way, you are using qualifiers and references. Good job, but did you think of adding Berlin as the sister city of 25 cities? Although the data you entered is correct, it is incomplete and you have—both unwilling and unknowingly—introduced an inconsistency. And that’s only, assuming you used the correct items and properties and did not make a typo while entering a statement. And thirdly, things change. Population numbers vary, organizations are dissolved and artists release new albums. Wikidata has the huge advantage that this change only has to be made in one place, but still: Someone has to do it and even more importantly, someone has to become aware of it.
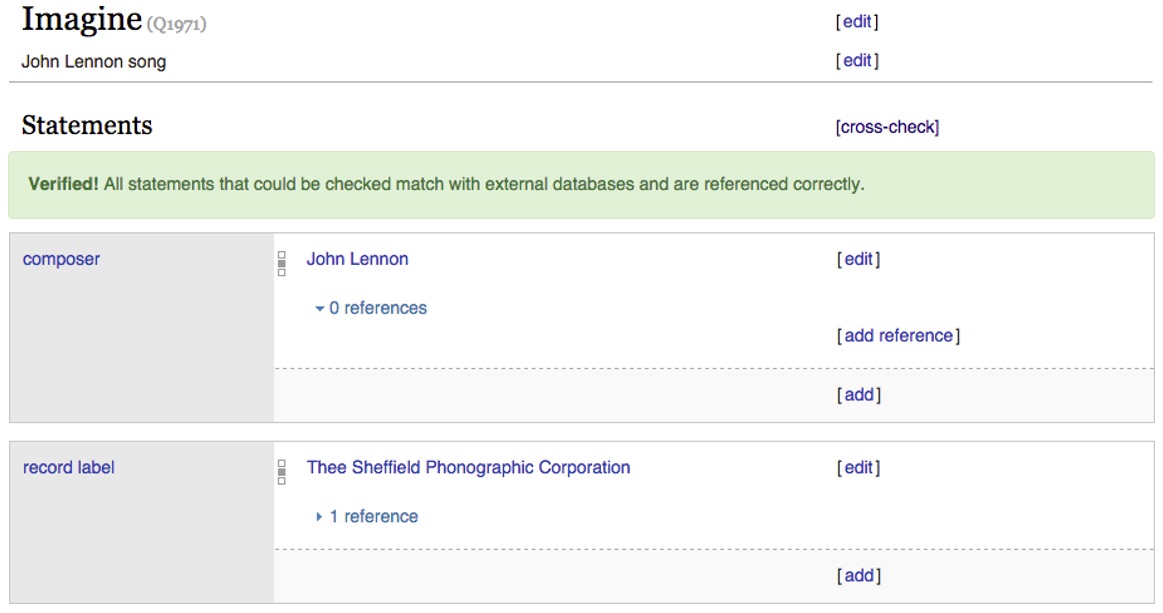 Facing the problems mentioned above, two projects have emerged. People using Wikidata are adding identifiers of external databases like GND, MusicBrainz and many more. So why not make use of them? We are developing a tool that scans an item for those identifiers and then searches in the linked databases for data against which it compares the items statements. This does not only help us verify Wikidata’s content and find mismatches that could indicate errors, but also makes us aware of changes. MusicBrainz is a specialist for artists and composers, GND for data related to people, and these specialists’ data is likely to be up to date. Using their databases to cross-check, we hope to be able to have the latest data of all fields represented in Wikidata.
Facing the problems mentioned above, two projects have emerged. People using Wikidata are adding identifiers of external databases like GND, MusicBrainz and many more. So why not make use of them? We are developing a tool that scans an item for those identifiers and then searches in the linked databases for data against which it compares the items statements. This does not only help us verify Wikidata’s content and find mismatches that could indicate errors, but also makes us aware of changes. MusicBrainz is a specialist for artists and composers, GND for data related to people, and these specialists’ data is likely to be up to date. Using their databases to cross-check, we hope to be able to have the latest data of all fields represented in Wikidata.
The second projects focuses on using constraints on properties. Here are some examples to illustrate what this means:
- Items that have the property “date of death” should also have “date of birth“, and their respective values should not be more than 150 years apart
- Properties like “sister city“ are symmetric, so items referenced by this statement should also have a statement “sister city“ linking back to the original item
- Analogously, properties like “has part” and “part of” are inverse and should be used on both items in a lot of cases
- Identifiers for IMDb, ISBN, GND, MusicBrainz etc. always follow a specific pattern that we can verify
- And so on…
 Checking these constraints and indicating issues when someone visits an items page, helps identify which statements should be treated with caution and encourages editors to fix errors. We are also planning to provide ways to fix issues (semi-)automatically (e.g. by adding the missing sister city when he is sure, that the city really has this sister city). We also want to check these constraints when someone wants to save a new entry. This hopefully prevents errors from getting into the system in the first place.
Checking these constraints and indicating issues when someone visits an items page, helps identify which statements should be treated with caution and encourages editors to fix errors. We are also planning to provide ways to fix issues (semi-)automatically (e.g. by adding the missing sister city when he is sure, that the city really has this sister city). We also want to check these constraints when someone wants to save a new entry. This hopefully prevents errors from getting into the system in the first place.
That’s about it – to keep up with the news visit our project page. We hope you are fond of our project and we appreciate your feedback! Contact information can also be found on the project page.




Mantra: könnt ihr bitte endlich englische Texte auf http://blog.wikimedia.en veröffentlichen? https://wmdeblog.local ist für Texte in deutscher Sprache gedacht.